Inheriting a Black Box
A month into my internship, I was assigned to work on a project involving the identification of Ayurvedic plants from images using a Convolutional Neural Network (CNN).
For readers unfamiliar with the term, a CNN is a type of deep learning model commonly used for image recognition tasks because it learns visual patterns such as edges, textures, and shapes directly from images.
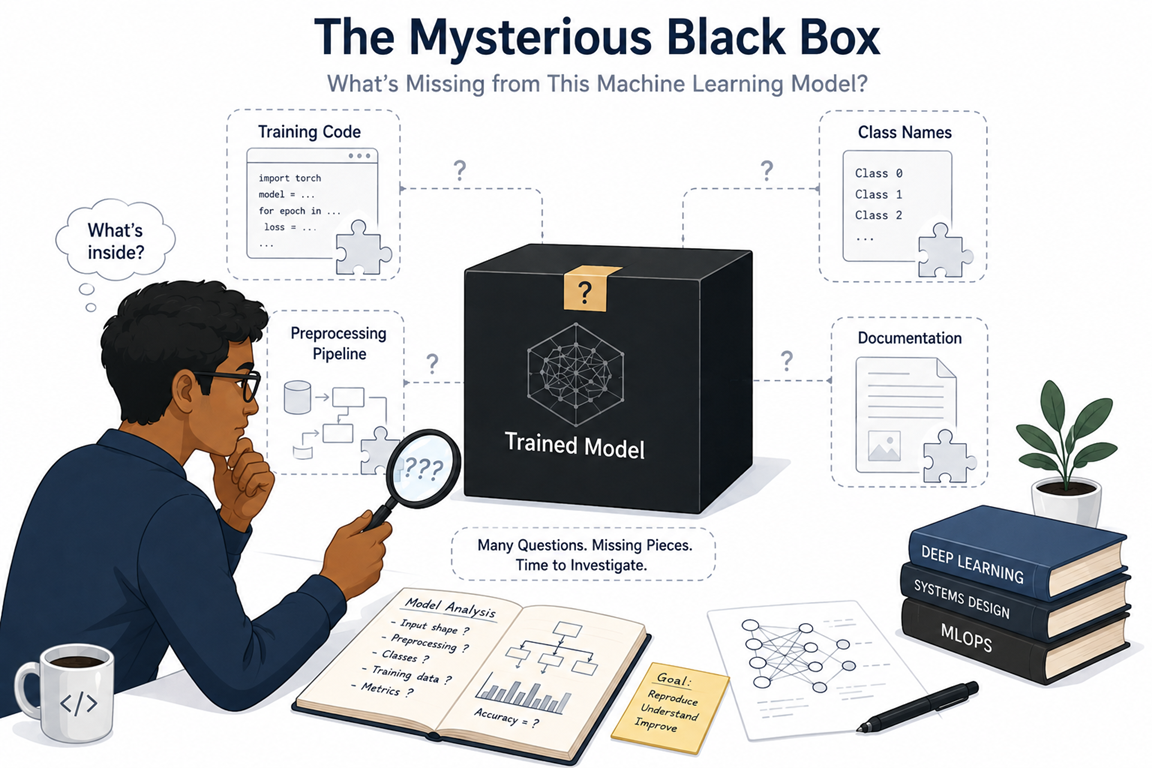
The project was already underway before I joined, so I inherited work that had been developed by previous interns and students. Along with the project, I received a trained CNN model and the dataset it had supposedly been trained on.
At first glance, that sounded sufficient.
It wasn't.
There was no training code. No preprocessing pipeline. No documentation explaining how predictions mapped to plant names. Just a trained model file that was approximately 6.92 GB in size.